Documentation and support
Usage of PhenDB
PhenDB offline
PhenDB is available as an online service, however, PICA models used by PhenDB can be retrieved from: http://phendb.csb.univie.ac.at/download
Please follow the instructions in the download section to learn how to use PICA on your local machine.
Using the Web Server
We try to support all modern browsers. The webapp has been tested on Chrome, Firefox, Safari and Edge. We recommend the usage of the latest version of these browsers, unfortunately we cannot support older versions (especially if they were released before 2016). If you notice any display error in the supported browsers, please contact us!
The PhenDB pipeline takes genomic bins from a metagenomics experiment as input, which may be provided as:
- Nucleotide fasta file (raw or gzip-compressed)
- Protein fasta file (raw or gzip-compressed)
- tar.gz or zip archive of the above
Please note that a flat file structure is required within archives. The current maximum file size for upload is 800 MB, the maximum file size per bin is 30 MB. Duplicate sequence files (determined by file content) and empty files will be silently dropped from the analysis. Due to the nature of our present machine learning models, archaeal bins cannot be provided with trait predictions at the moment.
To control the stringency of predictions, two kinds of quality cut-offs may be applied by the user:
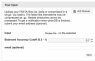
- Mean Balanced Accuracyis a confidence measure computed from completeness/contamination of the uploaded bin and the model's known predictive power at the bin’s completeness and contamination level. It can thus be interpreted as our confidence in the predictions of the model, given the bin's completeness and contamination. Values of balanced accuracy may range from 0.5 (predictions are expected to be random) to 1 (high expected correlation of predicted class and actual class; also note the prediction confidence). We suggest this measure as the user’s main option for tuning sensitivity vs. specificity of PhenDB predictions, as it scales with completeness and contamination of your input data.
- Prediction confidenceis the internal probability of class membership within the linear SVM model used by PICA (provided via Platt scaling). It can thus be seen as the confidence of the model in its prediction, given the data presented to it. Values for confidence range vom 0.5 (predictions are expected to be random) to 1 (PICA is highly confident with its prediction, given the set of input data)
Predictions below the chosen cut-off value (range: 0.5 - 1) are masked in the downloadable result ("n.d." instead of +/-).
As an additional filtering step applied after cut-off filtering, PhenDB masks predictions by hierarchical filtering based on known co-occurrence of traits. For example, a bin predicted as being Gram-positive does not receive a prediction with regards to the presence of T3SS and T6SS. Results filtered in this manner are marked with "n.c." (not calculated).
To our knowledge, not many freely available resources allow users to upload whole metagenomes for analysis. Despite high parallelization of workloads within submitted jobs, consecutively submitted jobs can only be processed serially due to computational limitations. Thus, dependent on the current length of the job queue, please note that waiting times may occur. After submitting your job to PhenDB, should your job be entered into the waiting queue, you will be kept updated about the current queue position.
After computation starts, progress may be checked by directly accessing the link to that site. When computation finishes, PhenDB provides a downloadable archive named after your job ID (i.e. the string after ../results/ in the URL). Your results are stored on our servers for 30 days.
Making Sense of the Downloadable Output
A full set of trait predictions and accompanying data is provided for your submission:
* the folder “individual_results”:
* a “{bin name}.traits.csv” file for every valid uploaded bin/genome. This file contains the model names, predictions (+/-/n.d./n.c.) along with prediction confidence and balanced accuracy values.
* the folder "summaries":
* "trait_counts.csv": A summary file that shows for each model how many bins/genomes were predicted as “+”, “-”, “n.d.” or “n.c.”
* "trait_summary_matrix.csv": A summary file containing the prediction for each bin and each model as a matrix. Possible values other than +/- are n.d. (masked due to accuracy or confidence cutoff) and n.c. (not calculated due to hierarchical filtering).
* "invalid_input_files.log.txt": If one or more of your uploaded files were invalid (e.g. not in FASTA format), a warning will appear to check this file. If all uploaded files are valid, this file is empty.
* "PICA_trait_descriptions.txt": Contains the names of PICA models and the traits they are testing for.
* "bin_summary.csv": Contains estimated completeness, contamination and strain heterogeneity of uploaded bins, as well as estimated taxonomic position computed by compleconta.
* "krona_taxonomy.html": A Krona plot of bin_summary.csv, detailing the placement of uploaded bins into taxa.
Release announcements
News

Latest publications
Contact
- +43 1 4277 76681
- +43 1 4277 876681
- contact.cube@univie.ac.at